
我把张小珺这期对姚顺宇的访谈转成文字稿,又做了一遍高亮。四个小时听下来,印象最深的是一件事:
AI 正在从神话现场,回到工程现场。
这篇更适合做 AI 产品、写代码,或者正在选 AI 方向的人看。尤其是已经开始觉得”只追模型新闻有点不够”的人。
我之前写过 /posts/claude-code-source-analysis/ 和 /posts/mac-ai-coding-tools/,更偏工具和工程细节。这一篇不讲教程,只看模型能力接近之后,哪些东西会继续拉开差距。
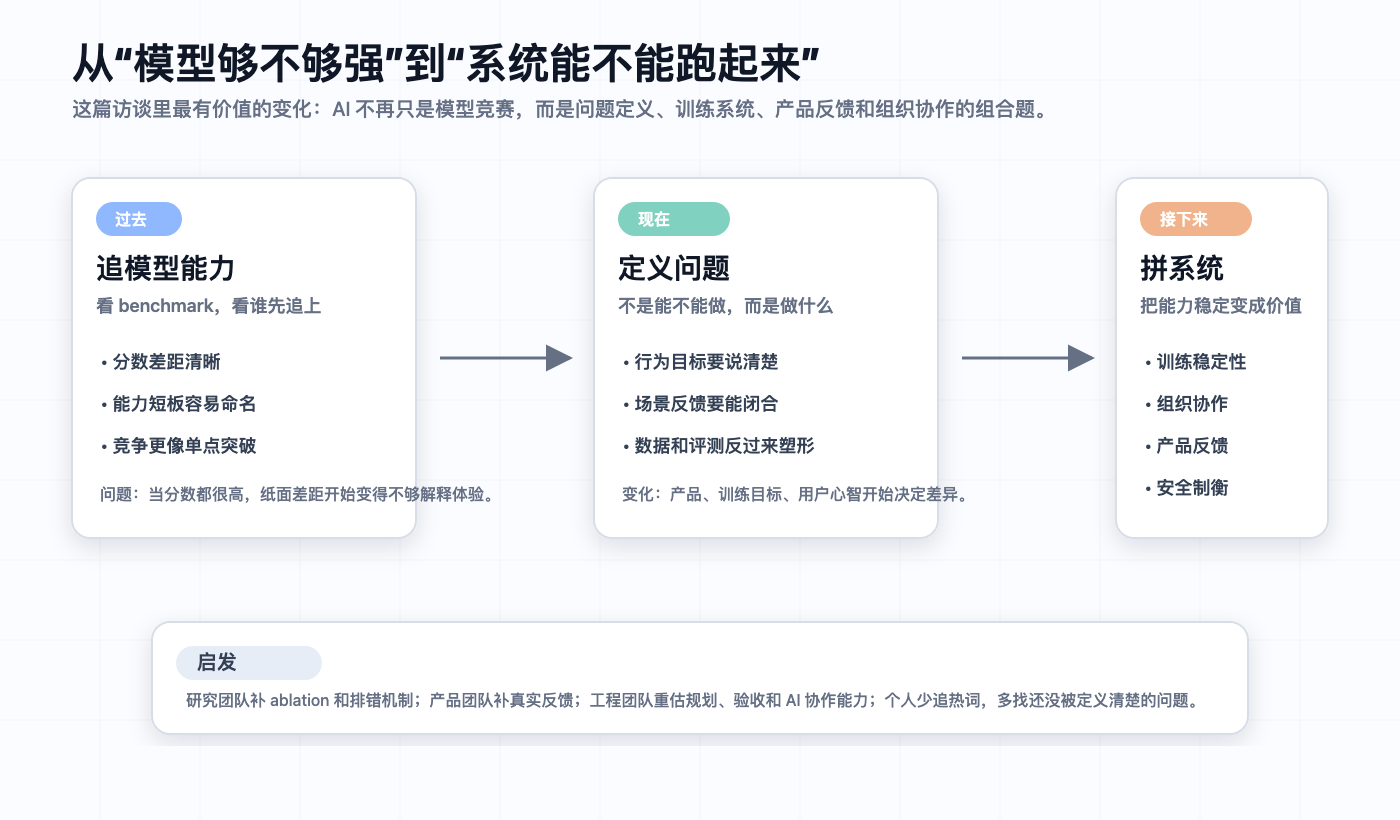
分数接近以后,难题才开始
过去两年看模型,很多人习惯先看榜。SWE-bench 高了几个点,数学题又过了哪条线,reasoning 比谁强,coding 比谁顺。这个阶段当然有意义——纸面上领先,体感上通常也会领先。
但访谈里有个判断我很认同:几个头部模型都挤进高分区间之后,benchmark 的解释力会下降。你今天再比较 Claude、Gemini、OpenAI,很难只靠一个分数判断谁好用。某个模型在工具使用上更顺,另一个在日常 reasoning 上更稳,还有一个在 coding 场景里追得很快。差异还在,只是不都写在一张榜单上。
竞争会往后推一层:模型应该表现出什么行为。
放到产品里看,这件事很具体。一个 coding agent 可以激进地改文件,也可以先解释计划;遇到不确定需求,可以先问人,也可以先做一个可回滚的草稿;做产品问答,可以追求”回答完整”,也可以优先承认”不知道”。这些产品判断不会从模型里自然长出来。场景、数据、训练目标、评测方式都会参与塑形。AI 行业正在从”能力有没有”转向”行为怎么定义”——后面这件事不热闹,但更难抄。
壳应用危险在入口层
现在很多 AI 产品的早期形态,都像是把模型能力接到一个工作流里。只要模型足够强,一些原本想不到的产品形态就会突然冒出来。OpenClaude 这类东西的价值,不一定在技术多神秘,而在它让更多人意识到模型可以串起很长的任务,可以调用不同工具,可以像一个粗糙但有用的工作台。
如果你的产品壁垒主要还停在”我把模型能力包装得更好看”,那模型公司迟早会看见。看见之后,要么自己做,要么收团队,要么把同类能力放进官方产品里。
Cursor 的焦虑就很典型。它有价值,模型公司才会盯上 coding 这个场景。它要继续保持位置,就不能永远只做模型能力的优秀入口。壳应用想活下来,需要尽快离开单纯入口层——要么占住用户心智,要么积累真实工作流数据,要么选足够窄、足够深的市场,让大公司短期内没有动力重兵投入。
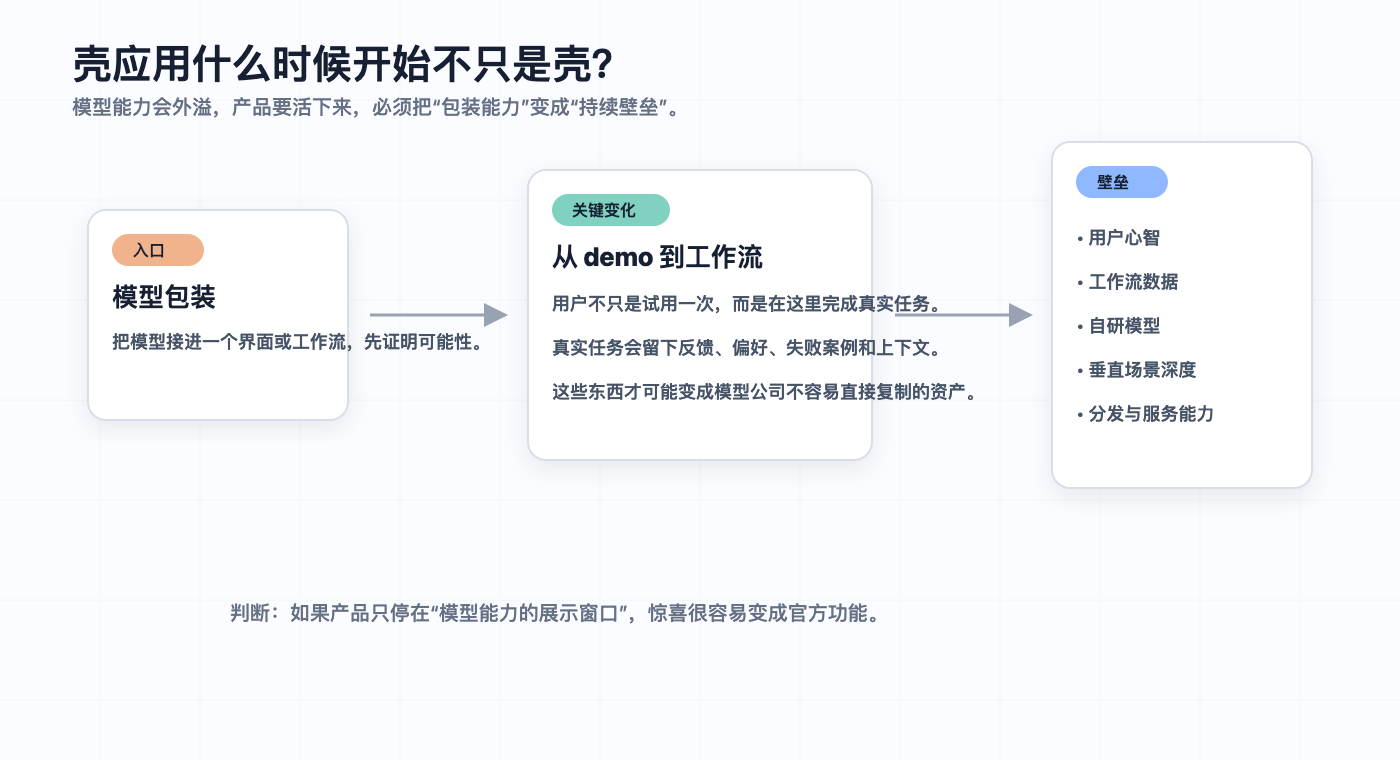
做 AI 产品时,有个问题可以直接问自己:做久了之后,用户为什么还留在我这里?如果回答只是”我调用的模型比较强”,那就还没到安全区。
Coding 会先把人重新分层
访谈里谈程序员的部分,是我听得最认真的一段。因为我自己的工作已经被 AI coding 改变了。
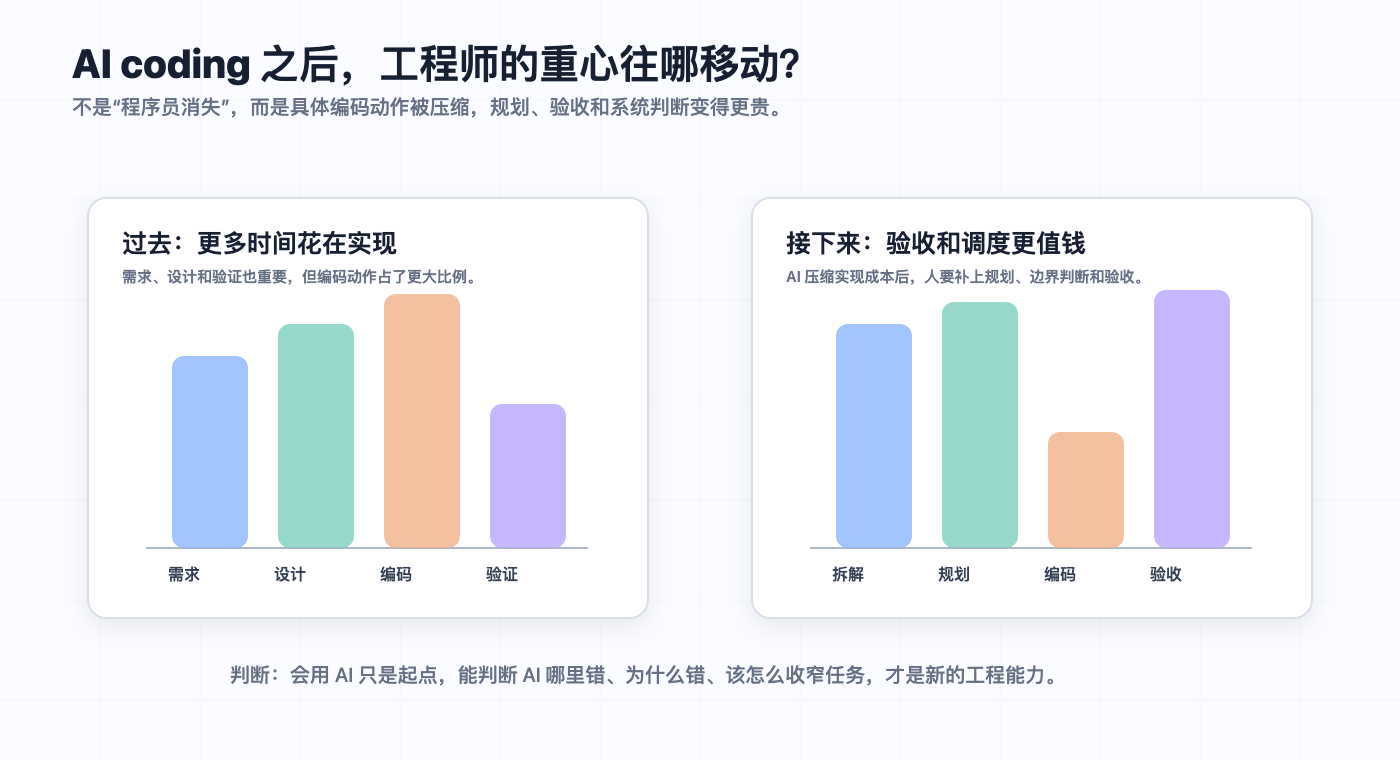
过去一个工程师的产出,里面混着很多层东西:理解需求、拆任务、设计边界、写实现、补测试、看日志、修 bug、和对面对齐上下文。AI coding 先吃掉的,主要是中间那层相对明确的实现工作。
这会造成一个结果:普通编码岗位会被挤压,强工程师的杠杆会变大。以前一个小团队才能完成的事情,现在可能一个强工程师带几个 agent 就能推进。这个人未必是手写代码最快的人,但他得能把模糊需求拆成可执行任务,看懂代码改动背后的系统影响,并且在 AI 犯错时知道是收窄问题还是换路径。
我拆 Claude Code 源码的时候就看到了——真正影响 Agent 体感的,往往是一句 prompt 背后的 runtime、session 管理、tool 调度、compact 策略和 permissions 链路。这些是 Agent 的”工程质量”,不是模型能力的”展示层”。换到团队工程里也一样:模型生成只是中间一环,前面的任务拆解和后面的验证调度,才决定它能不能进入真实工作流。
很多人把任务直接扔给模型,然后等一个看起来很完整的结果。小任务里没问题。一旦进入真实项目,边界条件、历史包袱、团队约定、运行环境、权限限制,模型不一定知道,知道了也不一定重视。
程序员要补的是把自己的工程判断显性化——哪些地方可以放手,哪些地方必须盯住。会用 AI 只是起点,能验收 AI 才是门槛。我最近经常提醒自己:每次提交前多看一眼 diff,不是因为我信不过模型,是因为我发现模型生成的代码里,最容易藏问题的地方恰好是我最不想看的那些——边界处理、权限判断、异步状态。这些地方模型不会主动提醒你,但出了问题又最难排查。
产品经理不容易训练
这期访谈里还有一个判断:产品经理未必会比程序员更早被 AI 直接替代。
关键在奖励信号。代码好坏,至少有一部分可以直接验证:能不能编译,测试过不过,线上有没有报错。产品就麻烦得多。一个需求到底好不好,可能要上线之后才知道。用户会不会用,为什么不用,是入口不对、时机不对,还是根本问题不存在——这些反馈都不干净。很多时候团队内部争了半天,也只是拿着不完整信号互相说服。
AI 可以帮产品经理做很多事:整理用户反馈、生成竞品分析、写 PRD 草稿、模拟用户路径。可最后那个判断——这个问题值不值得做,先做哪一刀,放弃什么——仍然要人来负责。越是奖励信号模糊的工作,越不能只追求自动化,更需要把判断过程写清楚。
研究像实验,也像工厂
姚顺宇从物理转到 AI,这条线值得看。我原本以为这部分会比较个人经历化,读下来发现,物理训练能迁移到 AI 研究,靠的主要是做实验的方式:先提出理解,再设计验证;发现结果不对,系统性排除变量;不要在没有反馈的地方过度自洽。
这套方法放到大模型训练里很接地气。训练系统里有太多东西互相影响:数据分布、强化学习目标、评测方式、基础设施、bug、随机性。一个 trick 在原系统里有效,换一个系统可能就失效,甚至反过来误导。很多经验不是孤立知识,它长在系统里——脱离原来的基础设施、数据和评测,把一个训练技巧单独搬走,很可能只搬走了表面动作。我们经常问”某某公司怎么做的”,更应该补一句:那套做法成立,需要哪些前提。前提不一样,抄作业就变成了抄姿势。
组织和安全都是硬问题
大模型训练这个场景里,组织是硬因素。前沿模型不是一个人把 idea 写进 notebook 就能跑出来的东西。算力调度、数据管线、训练稳定性、评测系统、产品反馈、研究判断,任何一个环节掉链子都可能拖偏结果。
访谈里对 Anthropic 和 Google DeepMind 的比较很有意思:Anthropic 更像纵向打穿,集中资源把一个方向推进到底;Google DeepMind 的优势在横向广度和工程土壤,技术更容易从研究溢出到产品。创业公司需要 make bet,大公司有资源但流程更重。个人开源项目可以先把可能性做出来,大公司要把它变成可承诺的产品,就背上安全、法务、品牌、稳定性的一整套负担。有些产品形态先从外部冒出来,原因也在这里——大公司研究员未必想不到,想到和发出去之间隔着很长一段组织成本。
AI 安全同理。不能指望某家公司单方面停下来解决整个行业的风险。技术浪潮一旦卷起来,单个玩家停下可能只是把主动权交给别人。更可行的路径是多方制衡、自动化监管、可解释性研究和更成熟的部署边界。安全重要,正因为重要,才不能寄托在”某个好公司永远克制”上。能力记录、场景边界、自动化监控、行业制衡——这些不如”AI 会不会毁灭人类”抓眼球,但更适合往前推进。
机会还在没定义清楚的地方
通用语言模型主战场已经挤满了。头部公司有模型、算力、数据、研究团队和产品入口,新人正面冲进去难度极高。
但访谈里提到的几个方向还可以继续看:long horizon 和 context management,解决系统如何处理更长任务;AI for research,让 AI 进入科学研究本身;多模态、机器人、世界模型和持续学习,还在更早的定义阶段。这些方向的共同点:问题还没被完全定义清楚。
如果一个赛道已经有清晰指标、清晰产品和清晰玩家,后来者能做,但更像在成熟牌桌上找位置。不确定的地方风险更大,也更可能长出新东西。刚入行的话,我会优先找两类位置:能接触真实系统的,和能接触真实问题的。不一定最光鲜,但更容易积累判断力。
写完这篇之后
回头检查自己手里的工作流有没有接住 AI:用 Agent 写代码时,验收标准有没有提前写清楚;做产品时,有没有保留失败样本和留存反馈;看一个 trick 时,有没有顺手查它在哪个训练系统里成立。
这几件事不新,也不漂亮,但离日常工作更近。
延伸阅读
- /posts/claude-code-source-analysis/:如果你想看 Agent runtime、tool 调度、compact 和 permissions 这些工程细节,可以继续读这篇。
- /posts/mac-ai-coding-tools/:如果你关心 AI coding 落到日常开发时,session、日志、文件定位和终端工作流怎么配,可以看这篇。
说明:本文基于小宇宙播客《140. 对姚顺宇的4小时访谈:请允许我小疯一下!在Anthropic和Gemini训模型、技术预测、英雄主义已过去》的逐字稿整理与个人理解写成。文中观点为转述和延展,不是嘉宾逐字引用。节目提到录制时间为 2026 年 3 月,AI 行业变化很快,具体公司和产品判断需要放回当时语境里看。